


Luis Mañez , Atlas Chief Architect
About this author
Published:

In the past few months, I have been fortunate to work on Atlas AI. This has provided me with deeper insight into AI token counter libraries and I thought I would share some of my learnings.
Let's start with what is an AI Assistant?
"AI Assistant is a smart chatbot that leverages your organization’s collective knowledge stored in Microsoft 365 and other enterprise sources. Employees engage with AI Assistant within popular Microsoft 365 applications like SharePoint or Teams, or through the Atlas AI interface. With AI Assistant, employees obtain immediate answers to critical questions and create authoritative content, all with the assurance of accuracy and validity."
If you have some experience on AI models, you are familiar with the Token concept (if not, here is a great introduction to generative language models and Tokens: https://bea.stollnitz.com/blog/how-gpt-works). In a nutshell, models take n tokens as input, and produce one token as output. Tokens are really important, first, because each different Model has a max number of tokens allowed per request (considering input and output), and even more, they invoice you depending on the number of tokens you consume (now I got your attention, didn’t I J). The following table contains the most known OpenAI models as of today (December 2023) with their max tokens allowed and pricing:
| Model | Max Tokens | Input | Output |
|
gpt-4-1106-preview |
128,000 tokens |
$0.01 / 1K tokens |
$0.03 / 1K tokens |
|
gpt-4-vision-preview |
128,000 tokens |
$0.01 / 1K tokens |
$0.03 / 1K tokens |
|
gpt-4 |
8,192 tokens |
$0.03 / 1K tokens |
$0.06 / 1K tokens |
|
gpt-4-32k |
32,768 tokens |
$0.06 / 1K tokens |
$0.12 / 1K tokens |
|
gpt-3.5-turbo |
4,096 tokens |
$0.0015 / 1K tokens |
$0.0020 / 1K tokens |
|
gpt-3.5-turbo-16k |
16,385 tokens |
$0.0010 / 1K tokens |
$0.0020 / 1K tokens |
Knowing this, you are likely to be thinking about counting tokens. Either your input prompt is coming directly from the user, or the prompt is pre-built, like when grounding (RAG pattern, etc), sooner than later, counting tokens is a must.
The algorithm for counting tokens, depends on the encoding name. Here’s a table with the encoding used by the different OpenAI models:
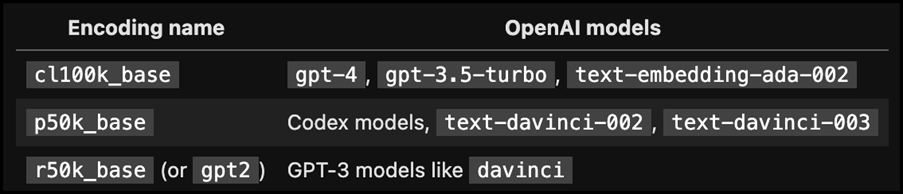
In this blog, I am only focusing on the most common Models: gpt-4 / gpt-3.5-turbo. In other words, the encoding cl100k_base.
There is a well-known opensource library called TikToken. This library is written in Python, which, for a dotnet person like me, is not cool. Luckily, there are some open source ports to dotnet. Below are examples of the dotnet token libraries.
GitHub repository: https://github.com/dmitry-brazhenko/sharptoken
// Get encoding by encoding name
var encoding = GptEncoding.GetEncoding("cl100k_base");
// Get encoding by model name
var encoding = GptEncoding.GetEncodingForModel("gpt-4");
var encoded = encoding.Encode("Hello, world!"); // Output: [9906, 11, 1917, 0]
var tokenCount = encoded.Count;
GitHub repository: https://github.com/microsoft/Tokenizer
var tokenizer = await TokenizerBuilder.CreateByEncoderNameAsync("cl100k_base");
var encode = tokenizer.Encode("Hello World", Array.Empty<string>());
var count = encode.Count;
GitHub repository: https://github.com/aiqinxuancai/TiktokenSharp
var tikToken = await TikToken.GetEncodingAsync("cl100k_base");
var encode = tikToken.Encode("Hello World", Array.Empty<string>());
var count = encode.Count;
We have seen how to count tokens using different libraries, but this is just counting tokens for a given text. However, if we are calling OpenAI API, and you want to exactly know how many tokens your Prompt has, you need to do some extra steps.
When calling OpenAI Chat completions endpoint, your message body looks something like this:
{
"messages": [
{
"role": "system",
"content": "You are a helpful assistant."
},
{
"role": "user",
"content": "Does Azure OpenAI support customer managed keys?"
},
{
"role": "assistant",
"content": "Yes, customer managed keys are supported by Azure OpenAI."
},
{
"role": "user",
"content": "Do other Azure AI services support this too?"
}
],
"temperature": 0,
"top_p": 1,
"max_tokens": 500,
"stop": null,
"stream": false
}
The number of tokens in this case, is not just to sum up the number of tokens of each message content. There is another algorithm to calculate this token count, and you can find the Python version here: https://github.com/openai/openai-cookbook/blob/feef1bf3982e15ad180e17732525ddbadaf2b670/examples/How_to_count_tokens_with_tiktoken.ipynb (section number 6)
It also depends in the model, but for gpt-3 and gpt-4, the pseudo code would be:
for each message
messagesTokenCount = token_count(role.value) + token_count(content.value) + 3
totalTokenCount = messagesTokenCount + 3
Note: As mentioned before, each Model has a max number of tokens (i.e: gpt-4 has 8,192 max tokens). That number includes the input and output. The output depends on the model’s response, but when calling the API, you tell the model the max number of tokens that they can “spend” in the response. So, if the model allows 8192 tokens, and when calling the API, you set the max_tokens to 1000, your input cannot have more than 7192 tokens.
This Token counting operations are not cheap, and performance is a key part if you need to count tokens in a bunch of very long strings. Below are some benchmarks from the 3 libraries.
This is the method that I have run for each of the libraries:
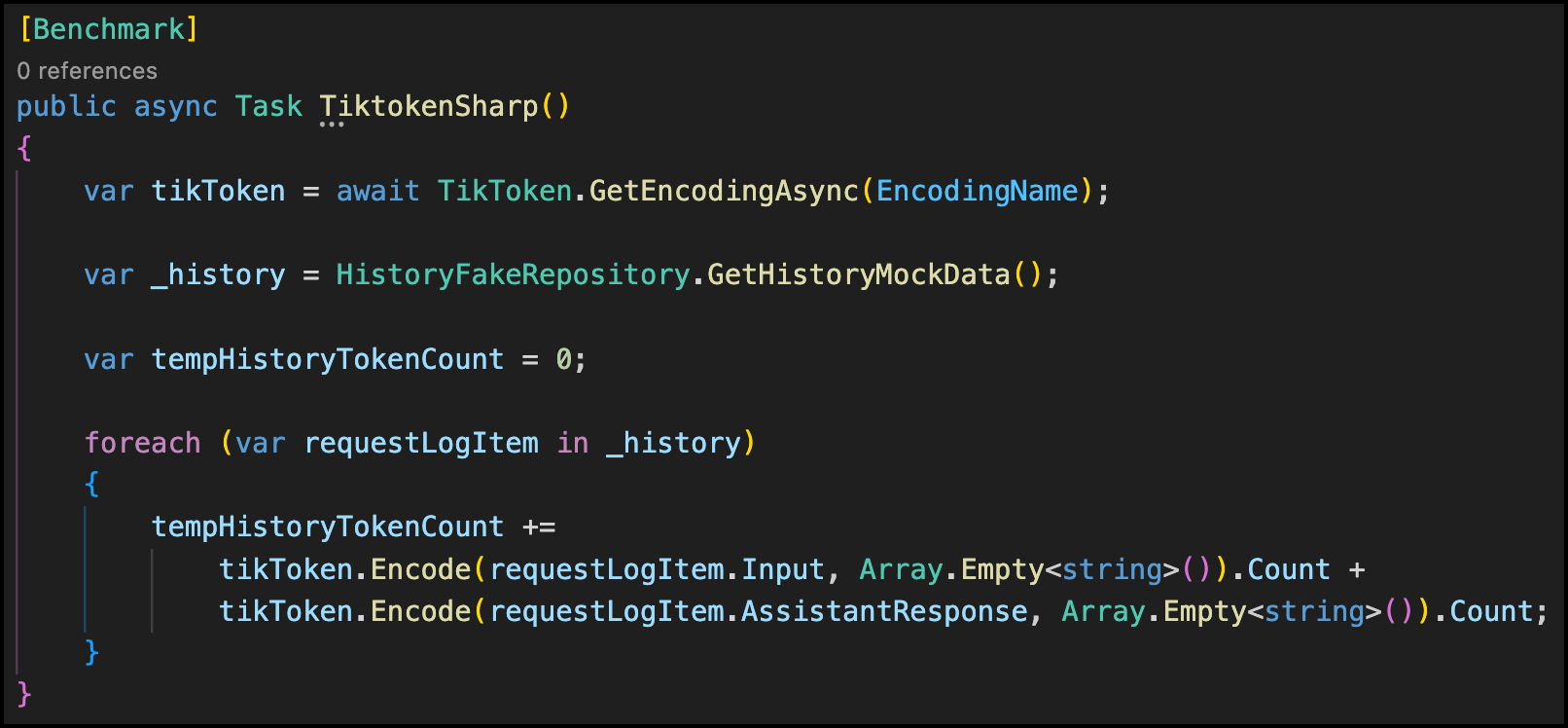
Basically, I am just getting 7 very long strings (cannot copy here the values, as are real data from one of our Tenants, but trust me, each item has a reasonable long text). Then, I’m just calculating the number of tokens of each item and sum them up.
Here are the benchmarks:
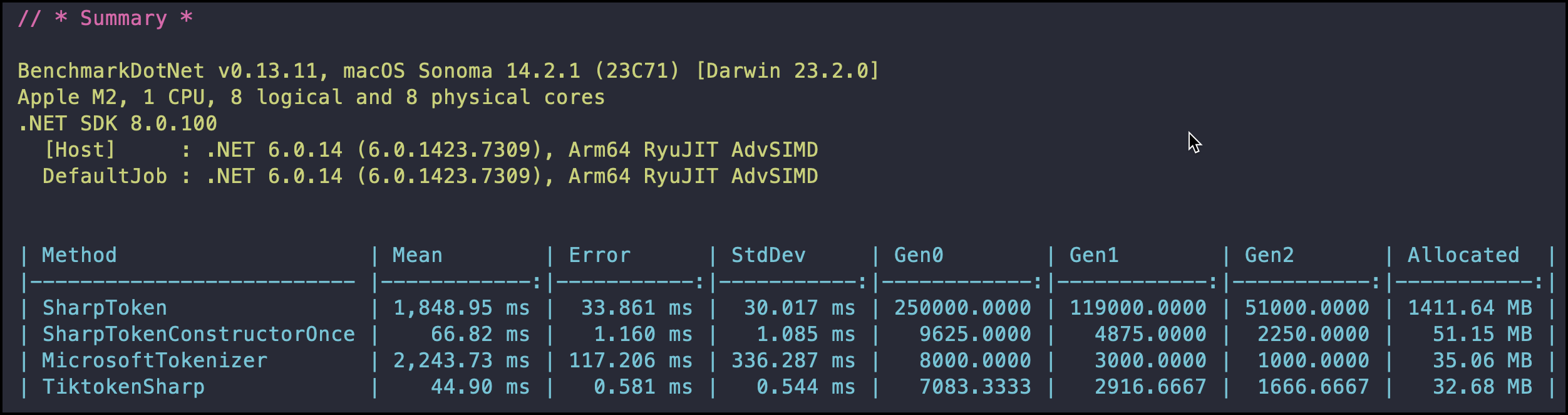
The SharpToken and SharpTokenConstructorOnce, are the same code, but in the second one, there is only one call to the code:
var encoding = GptEncoding.GetEncoding(EncodingName);
While in the first one, this code is called with each item in the list. This is just to prove that in the 3 libraries, the method that returns the Encoding is expensive, so prepare your code to call it as few as possible.
As you can see in the Benchmarks, the TikToken library is the fastest one, followed closely by SharpToken, and then the Microsoft one (which is curious, cos the MS one, allocates quite a few less memory than SharpToken).
Hope this helps you to understand a bit more about tokens and how to deal with them.


